
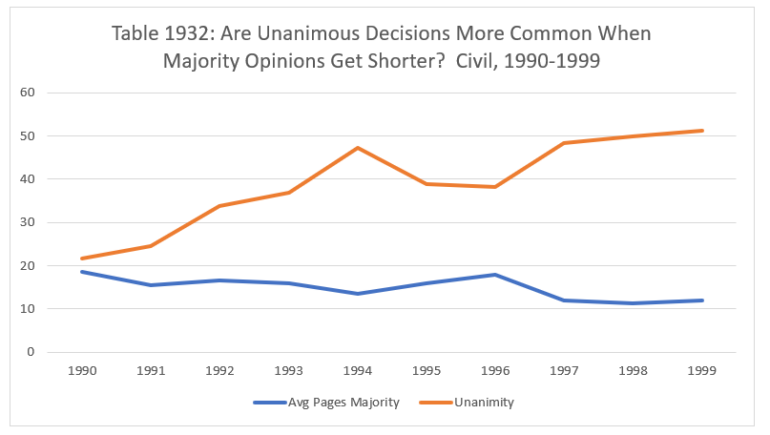
Last time, we showed that between 1990 and 1999, as majority opinions in civil cases got substantially shorter, unanimity became significantly more common. What about the criminal docket?
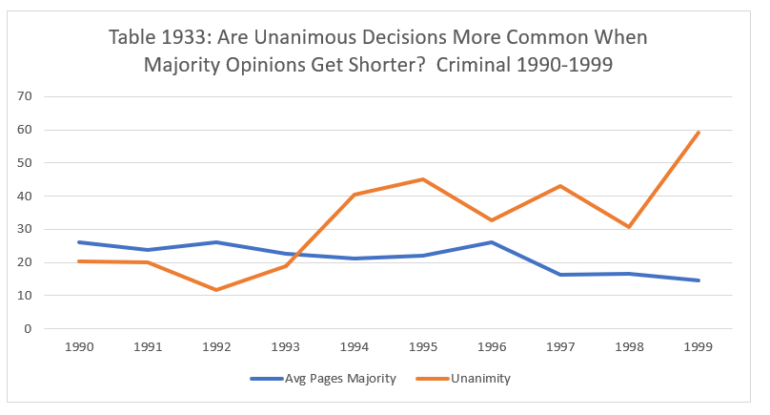
The effect on the criminal side of the docket was even more noticeable.
In 1990, the average majority opinion in a criminal case was 25.97 pages. By 1994, the average had decline to 21.05 pages. The average increased a bit in the following two years, but then dropped sharply, to 16.17 in 1997, 16.54 in 1998 and only 14.45 in 1999.
During the decade, unanimous decisions became significantly more common. In 1990, only 20.29% of the Court’s criminal decisions were unanimous. That had fallen to 11.63% by 1992. But after that, unanimity increased sharply, reaching 45.07% in 1995, 43.1% in 1997 and 59.18% of the Court’s criminal decisions in 1999.
Next week, we’ll turn our attention to the next decade: 2000 to 2009.
Image: The Burning of Chicago lithograph
Image courtesy of Smithsonian National Museum of American History (Creative Commons License)













 This time, we’re reviewing the decline in Appellate Court criminal dockets between 2001 and 2010.
This time, we’re reviewing the decline in Appellate Court criminal dockets between 2001 and 2010.
 Last time we reviewed the data for civil dockets in the Districts of the Appellate Court for the years 1997 through 2000. Today, we’re looking at the data for the years 2001 through 2010.
Last time we reviewed the data for civil dockets in the Districts of the Appellate Court for the years 1997 through 2000. Today, we’re looking at the data for the years 2001 through 2010.



